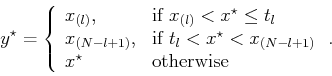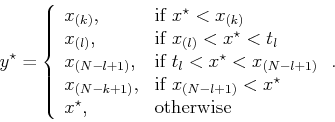|
|
|
|
Nonlinear structure-enhancing filtering using plane-wave prediction |
In this appendix, we review lower-upper-middle (LUM)
filters introduced by Hardie and Boncelet (1993). Consider a window function
containing a set of ![]() samples centered about the sample
samples centered about the sample ![]() . We
assume
. We
assume ![]() to be odd. This set of observations will be denoted by
to be odd. This set of observations will be denoted by
![]() . The rank-ordered set can be written as
. The rank-ordered set can be written as
The estimate of the center sample will be denoted ![]() .
.
Thus, the output of the lower-upper-middle (LUM)
smoother is ![]() if
if
![]() . If
. If
![]() , then
the output of the LUM smoother is
, then
the output of the LUM smoother is ![]() . Otherwise the output
of the LUM smoother is simply
. Otherwise the output
of the LUM smoother is simply ![]() .
.
Then, the output of the lower-upper-middle (LUM)
sharpener with parameter ![]() is given by
is given by
Thus, if
![]() , then
, then ![]() is shifted outward to
is shifted outward to
![]() or
or ![]() according to which is closest to
according to which is closest to
![]() . Otherwise the sample
. Otherwise the sample ![]() is unmodified. By changing the
parameter
is unmodified. By changing the
parameter ![]() , various levels of sharpening can be achieved. In the
case where
, various levels of sharpening can be achieved. In the
case where ![]() , no sharpening occurs and the
lower-upper-middle (LUM) sharpener is simply an
identity filter. In the case where
, no sharpening occurs and the
lower-upper-middle (LUM) sharpener is simply an
identity filter. In the case where ![]() , a maximum amount of
sharpening is achieved since
, a maximum amount of
sharpening is achieved since ![]() is being shifted to one of the
extreme-order statistics
is being shifted to one of the
extreme-order statistics ![]() or
or ![]() .
.
|
|
|
|
Nonlinear structure-enhancing filtering using plane-wave prediction |