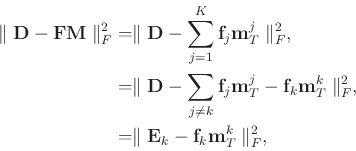|
|
|
|
Fast dictionary learning for noise attenuation of multidimensional seismic data |
Next: Fast dictionary learning by Up: Method Previous: Problem formulation
|
|
|
|
Fast dictionary learning for noise attenuation of multidimensional seismic data |
It is now obvious that the ![]() th dictionary in
th dictionary in
![]() is updated by minimizing the misfit between the rank-1 approximation of
is updated by minimizing the misfit between the rank-1 approximation of
![]() and the
and the
![]() term. The rank-1 approximation is then solved using the singular value decomposition (SVD).
term. The rank-1 approximation is then solved using the singular value decomposition (SVD).
A problem in the direct use of SVD for rank-1 approximation of
![]() is the loss of sparsity in
is the loss of sparsity in
![]() . After SVD on
. After SVD on
![]() ,
,
![]() is likely to be filled. In order to solve such problem, K-SVD restricts minimization of equation 5 to a small set of training signals
is likely to be filled. In order to solve such problem, K-SVD restricts minimization of equation 5 to a small set of training signals
![]() . To achieve this goal, one can define a transformation matrix
. To achieve this goal, one can define a transformation matrix
![]() to shrink
to shrink
![]() and
and
![]() by rejecting the zero columns in
by rejecting the zero columns in
![]() and zero entries in
and zero entries in
![]() . First one can define a set
. First one can define a set
![]() , which selects the entries in
, which selects the entries in
![]() that are non-zero. One then constructs
that are non-zero. One then constructs
![]() as a matrix of size
as a matrix of size
![]() with ones on the
with ones on the
![]() entries and zeros otherwise.
entries and zeros otherwise.
Applying
![]() to both
to both
![]() and
and
![]() , then the objective function in equation 5 becomes
, then the objective function in equation 5 becomes
|
|
|
|
Fast dictionary learning for noise attenuation of multidimensional seismic data |