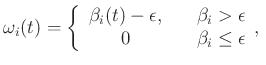|
|
|
|
Application of principal component analysis in weighted stacking of seismic data |
Next: Examples Up: Method Previous: Low-rank approximation of the
|
|
|
|
Application of principal component analysis in weighted stacking of seismic data |
|
|
|
|
Application of principal component analysis in weighted stacking of seismic data |