 |
 |
 |
 | New insights into one-norm solvers from the Pareto curve |  |
![[pdf]](icons/pdf.png) |
Next: Practical considerations
Up: Comparison of one-norm solvers
Previous: Comparison of one-norm solvers
|
|---|
plot
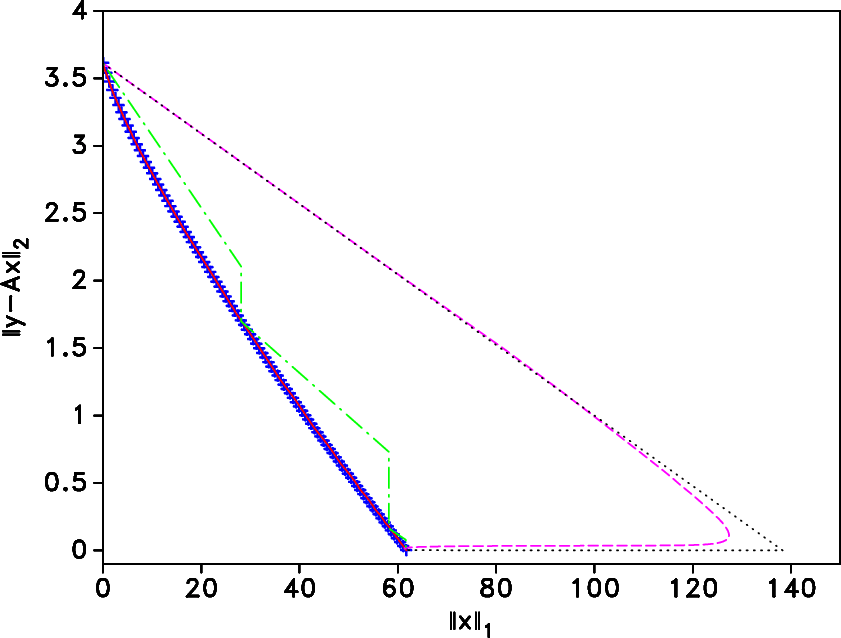
Figure 2. Pareto curve and solution paths
(large enough number of iterations) of four solvers for a BP problem. The symbols + represent a sampling of the Pareto curve. The
solid (--) line, obscured by the Pareto curve, is the solution path
of ISTc, the chain (-
problem. The symbols + represent a sampling of the Pareto curve. The
solid (--) line, obscured by the Pareto curve, is the solution path
of ISTc, the chain (-  -) line the path of SPGL
-) line the path of SPGL ,
the dashed (- -) line the path of IST, and the dotted (
,
the dashed (- -) line the path of IST, and the dotted ( )
line the path of IRLS.
)
line the path of IRLS.
|
|---|
![[png]](icons/viewmag.png) ![[scons]](icons/configure.png)
|
|---|
Figure 2 shows the solution paths of the
four solvers as they converge to the BP
solution. The starting
vector provided to each solver is the zero vector, and hence the paths
start at
 --point
--point  in Figure 1. The number of iterations is large enough
for each solver to converge, and therefore the solution paths end at
in Figure 1. The number of iterations is large enough
for each solver to converge, and therefore the solution paths end at
 --point
--point  in Figure
1.
in Figure
1.
The two solvers SPG
and ISTc approach the BP
solution from
the left and remain close to the Pareto curve. In contrast, IST and
IRLS aim at a least-squares solution before turning back towards the
BP
solution. ISTc solves QP for a decreasing sequence
for a decreasing sequence
 . The starting vector for QP
. The starting vector for QP
 is the
solution of QP
is the
solution of QP
 , which is by definition on the Pareto
curve. This explains why ISTc so closely follows the curve.
SPG
solves a sequence of LS
, which is by definition on the Pareto
curve. This explains why ISTc so closely follows the curve.
SPG
solves a sequence of LS problems for an increasing
sequence of
problems for an increasing
sequence of
 , hence the vertical segments
along the SPG
solution path. IST solves QP
, hence the vertical segments
along the SPG
solution path. IST solves QP . Because
there is hardly any regularization, IST first works towards minimizing
the data misfit. When the data misfit is sufficiently small, the
effect of the one-norm penalization starts, yielding a change of
direction towards the BP
solution. IRLS solves a sequence of
weighted, damped, least-squares problems. Because the weights are
initialized to ones, IRLS first reaches the standard least-squares
solution. The estimates obtained from the subsequent reweightings have
a smaller one norm while maintaining the residual (close) to zero.
Eventually, IRLS gets to the BP
solution.
. Because
there is hardly any regularization, IST first works towards minimizing
the data misfit. When the data misfit is sufficiently small, the
effect of the one-norm penalization starts, yielding a change of
direction towards the BP
solution. IRLS solves a sequence of
weighted, damped, least-squares problems. Because the weights are
initialized to ones, IRLS first reaches the standard least-squares
solution. The estimates obtained from the subsequent reweightings have
a smaller one norm while maintaining the residual (close) to zero.
Eventually, IRLS gets to the BP
solution.
|
|
|
|
| New insights into one-norm solvers from the Pareto curve | |
|
Next: Practical considerations
Up: Comparison of one-norm solvers
Previous: Comparison of one-norm solvers
2008-03-27