 |
 |
 |
 | Multidimensional recursive filter preconditioning
in geophysical estimation problems |  |
![[pdf]](icons/pdf.png) |
Next: Data-space regularization (model preconditioning)
Up: Review of regularization in
Previous: Review of regularization in
Model-space regularization implies adding equations to
system (1) to obtain a fully constrained (well-posed)
inverse problem. The additional equations take the form
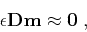 |
(2) |
where 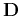 is a linear operator that represents additional
requirements for the model, and
is a linear operator that represents additional
requirements for the model, and 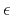 is the scaling parameter.
In many applications, can be thought of as a filter,
enhancing undesirable components in the model, or as the operator of
a differential equation that we assume the model should satisfy.
is the scaling parameter.
In many applications, can be thought of as a filter,
enhancing undesirable components in the model, or as the operator of
a differential equation that we assume the model should satisfy.
The full system of equations (1-2) can be
written in a short notation as
![\begin{displaymath}
\mathbf{G_m m} = \left[\begin{array}{c} \mathbf{L} \epsi...
...bf{d} \mathbf{0} \end{array}\right] =
\hat{\mathbf{d}}\;,
\end{displaymath}](img10.png) |
(3) |
where
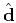 is the augmented data vector:
is the augmented data vector:
![\begin{displaymath}
\hat{\mathbf{d}} = \left[\begin{array}{c} \mathbf{d} \mathbf{0}
\end{array}\right]\;,
\end{displaymath}](img12.png) |
(4) |
and 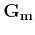 is a column operator:
is a column operator:
![\begin{displaymath}
\mathbf{G_m} = \left[\begin{array}{c} \mathbf{L} \epsilon \mathbf{D}
\end{array}\right]\;.
\end{displaymath}](img14.png) |
(5) |
The estimation problem (3) is fully constrained. We can
solve it by means of unconstrained least-squares optimization,
minimizing the least-squares norm of
the compound residual vector
![\begin{displaymath}
\hat{\mathbf{r}} = \hat{\mathbf{d}} - \mathbf{G_m m} =
\left...
...thbf{d - L m} - \epsilon \mathbf{D m}
\end{array}\right]\;.
\end{displaymath}](img15.png) |
(6) |
The formal solution of the regularized optimization problem has the
known form (Parker, 1994)
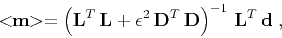 |
(7) |
where
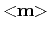 denotes the least-squares estimate of
denotes the least-squares estimate of 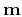 ,
and
,
and 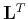 denotes the adjoint operator.
One can carry out the optimization iteratively with the help of the
conjugate-gradient method (Hestenes and Steifel, 1952) or its analogs
(Paige and Saunders, 1982).
denotes the adjoint operator.
One can carry out the optimization iteratively with the help of the
conjugate-gradient method (Hestenes and Steifel, 1952) or its analogs
(Paige and Saunders, 1982).
In the next subsection, we describe an alternative formulation of the
optimization problem.
|
|
|
|
| Multidimensional recursive filter preconditioning
in geophysical estimation problems | |
|
Next: Data-space regularization (model preconditioning)
Up: Review of regularization in
Previous: Review of regularization in
2013-03-03