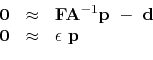|
|
|
|
Preconditioning |
Burdened by a problem of oppressive size, any trick, honest or sly, is nice to know. I will tell you a trick that is widely used. Many studies are done ignoring (abandoning) the model styling regression (second fitting regression as follows):
Why does this crude approximation seem to work?
The preconditioner is based on an analytic solution
(
![]() is an inverse)
to the regularization,
so naturally, early iterations tend to already fit the regularization,
so early iterations are struggling instead to fit the data.
The longer you run though, the better the data fit,
and the more the actual regularization should be coming into play.
But ongoing research often fails to run that far.
is an inverse)
to the regularization,
so naturally, early iterations tend to already fit the regularization,
so early iterations are struggling instead to fit the data.
The longer you run though, the better the data fit,
and the more the actual regularization should be coming into play.
But ongoing research often fails to run that far.
Figure 8 shows the idea
that early iterations fit the straight lines.
Straight lines honor the preconditioner.
At later iterations the data fits better.
Why do straight-line solutions honor the regularization?
Refer to the discussion near Figure ![]() .
.
|
|
|
|
Preconditioning |